Cloudflare turns AI crawl control into a publisher workflow with Search, Agent and Training policies

Cloudflare's July 1, 2026 Content Independence Day releases amount to a new operating model for publishers and ecommerce brands that treat crawler management as a binary "allow bots" or "block bots" decision. In posts on AI traffic options, AI search economics, and Attribution Business Insights, plus Cloudflare docs updates, the company split AI traffic into Search, Agent, and Training.
That distinction matters because "AI traffic" now includes very different activities. Some crawlers are indexing pages for later answer generation. Some are acting in real time on behalf of a user. Others are collecting content to train or fine-tune models.
What changed
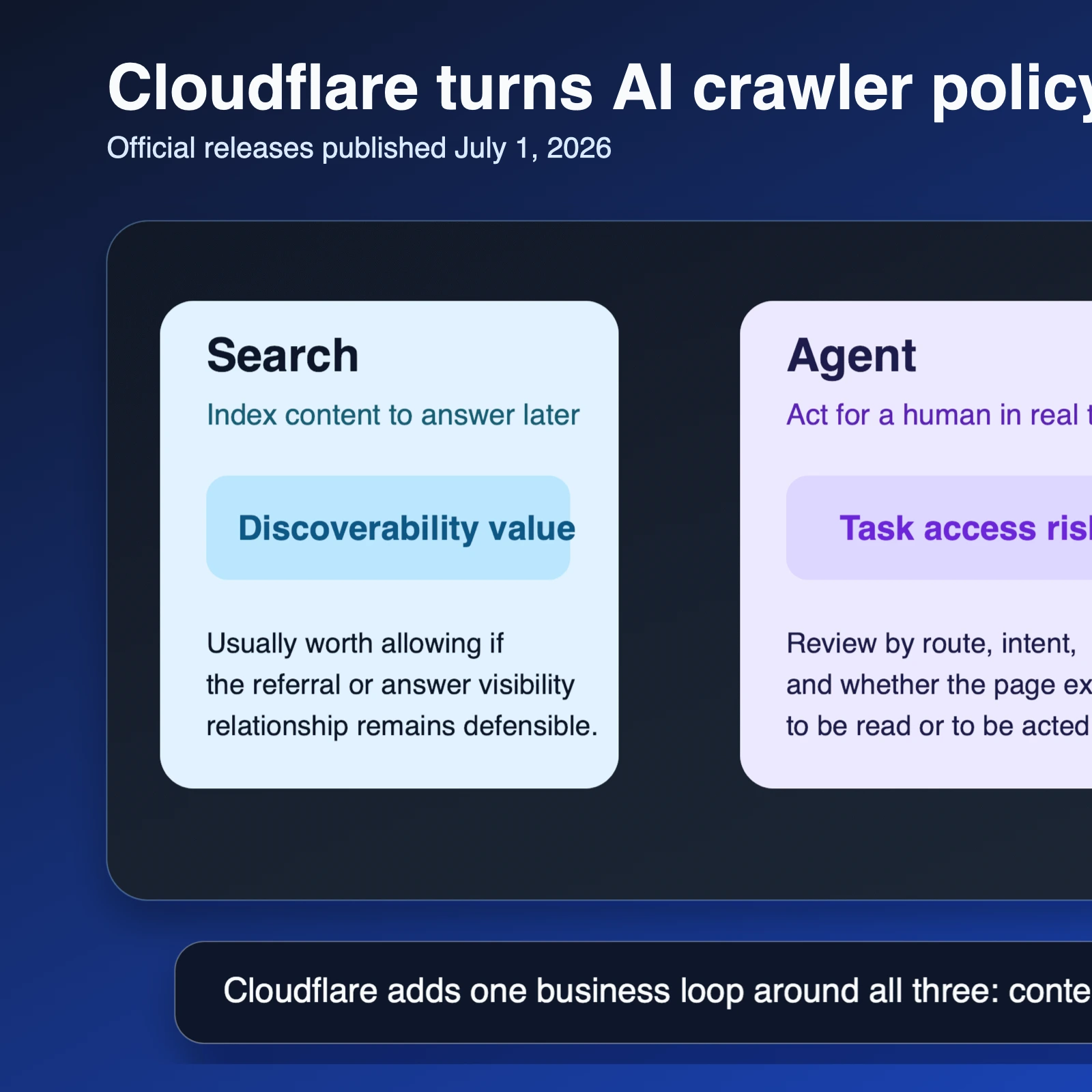
The official July 1 Cloudflare product post says all customers can now manage AI crawlers by behavior instead of relying on a single Block AI Bots preset. The three main categories are Search, Agent, and Training. Search refers to crawlers collecting or indexing content so they can answer questions later. Agent refers to automated tools acting in real time for a human, such as fetch bots or browser-use agents. Training refers to crawlers collecting content to train or fine-tune a model. Cloudflare's updated bot documentation confirms those policies can be configured separately and that each one can be set to block on all pages, block on pages with ads, or allow.
Cloudflare also published a time-bound default change. Both the product post and the July 1 changelog entry say that on September 15, 2026, new domains onboarding to Cloudflare will block Training and Agent bots by default on pages that display ads, while Search remains allowed by default. Mixed-purpose crawlers combining Search and Training will be affected by the stricter Training rule unless a site owner opts out beforehand.
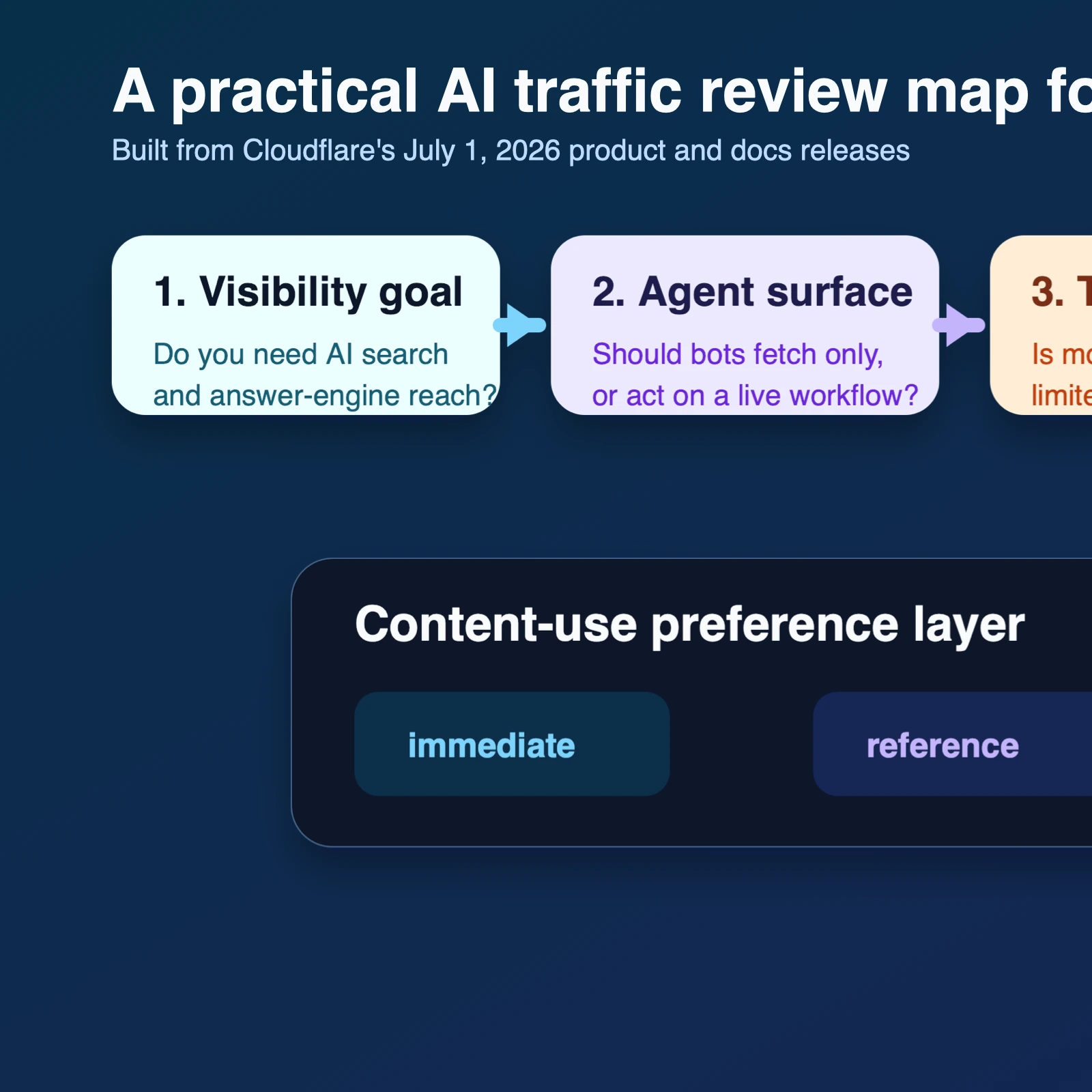
The release did not stop at controls. Cloudflare's Attribution Business Insights announcement says Bot Management customers now get a dashboard with site-wide and per-operator crawl-to-referral ratios, bot traffic to content pages, and action status by operator. The broader bots changelog adds that Enterprise Bot Management customers also get BotBase, a searchable catalog of tracked bots and agents with behavior classifications and detection IDs. The managed robots.txt documentation also adds a new use content signal so site owners can express whether bots may only interact immediately, may reference and link back, or may summarize and reproduce content more fully.
| Confirmed release point | Official source | Practical implication |
|---|---|---|
| AI traffic can now be managed by Search, Agent, and Training behavior. | Cloudflare blog, July 1, 2026 and bot docs | Publishers can stop using one rule for very different kinds of automated access. |
| On September 15, 2026, new Cloudflare domains will block Training and Agent bots on pages with ads by default. | Cloudflare changelog, July 1, 2026 | Ad-funded sites need to review default behavior before future launches or migrations. |
| Attribution Business Insights shows crawl-to-referral ratios site-wide and per bot operator. | Cloudflare blog, July 1, 2026 | Teams can compare who consumes content versus who actually sends traffic or value back. |
| BotBase classifies tracked bots and exposes detection IDs for rule targeting. | Cloudflare bots changelog | Security and business teams get a shared inventory instead of opaque bot labels. |
| Managed robots.txt now supports a `use` signal with `immediate`, `reference`, and `full` levels. | Cloudflare managed robots.txt docs | Sites can express preferred downstream content use, not only allow versus block. |
Why it matters
For marketers, publishers, and growth operators, the most important change is that crawler policy is becoming revenue policy. Cloudflare says in its AI search post that more than 50% of traffic online is now non-human, and in its Attribution Business Insights post it argues that some AI operators can show crawl-to-referral ratios ranging from 118:1 to nearly 50,000:1. Referral value, infrastructure cost, visibility, and rights management can no longer be treated as separate conversations.
This is also a GEO and answer-engine story, not just a security story. If you block everything, you may lose discoverability in AI-assisted search and agent surfaces. If you allow everything, you may be giving away expensive content to systems that summarize it without creating traffic, leads, subscriptions, or attributable revenue. Cloudflare is trying to make that tradeoff more granular: allow Search, limit Training, inspect Agent activity, and look at measured value before changing policy. That approach aligns well with the GEO Visibility Checklist, the guide to tracking brand mentions and visibility, and the Digital Marketing Budget Planner.
Who is affected
The first group is ad-funded publishers and content businesses that depend on pageviews, subscriptions, affiliate traffic, or direct audience relationships. Cloudflare's September 15 defaults explicitly call out pages with ads.
The second group is ecommerce and software brands that want to remain visible in AI search results without offering unlimited training rights.
The third group is internal operators: SEO teams, growth teams, web platform owners, and security teams. BotBase, content-use signals, and crawl-to-referral dashboards give them a shared vocabulary.
What to do next
- Inventory which parts of your site are monetized by ads, subscriptions, lead capture, or product conversion.
- Separate your preferred treatment for Search, Agent, and Training traffic instead of keeping one generic AI policy.
- Review whether your current
robots.txtstance matches your real business preference for reuse, excerpting, and summarization. - If you use Cloudflare Bot Management, inspect crawl-to-referral ratios by operator before changing allow or block rules.
- Pair crawler policy work with visibility measurement using /tools/geo-visibility-checklist so discoverability and control are reviewed together.
- Model the revenue impact of lost or improved visibility with the Marketing ROI Calculator or Digital Marketing Budget Planner instead of arguing only from principle.

What remains uncertain
Cloudflare has given strong signals, but not every outcome is settled. The company says the new economics of AI search are still experimental, and its July 1 search post describes current compensation and smarter-crawling efforts as programs being tested with partners rather than as mature standards. The use signal in managed robots.txt is still a preference expression.
So the practical conclusion on July 4, 2026 is not that publisher-AI economics are solved. It is that Cloudflare has turned them into an operational surface. Teams now have a clearer way to ask five questions at once: which bots are helping, which are extracting, what access they want, what reuse they permit, and whether AI visibility is producing value in return.